この記事は、Insurtechラボ202306アドベントカレンダーの15日目の投稿となります。
AI界隈が爆速で進化していきますね。正直追い切れないのですが、コード生成AIが話題となったとあっては、職業的プログラマーとしても無視できません。自分の仕事をアシストしてくれるなら、是非活用したいと思い、いくつか触ってみることにしました。
「コード生成AI」って何だ?
自然言語で指示を出すとコードを書いてくれるAIのことを指します。
コード生成AIには、「Advanced Data Analysis(旧Code Interpreter)」「Code Llama」「GitHub Copilot」「Amazon CodeWhisperer」「StableCode」・・・など非常に沢山あります。
私自身はAWSをよく利用しているので、CopilotとCodeWispererあたりを「やってみた」が有用なんだろうなと思っていたのですが、「Open Interpreter」というコード生成AIを利用したオープンソースが熱いようなので、この祭りに乗っかることにしてみました。
Open Interpreterとは?
これ自体がAIという訳ではなく、コード生成系AIをローカルPCで動かしてしまおう!、というオープンソースプロダクト(ライセンスは「MIT License」)です。ChatGPTのAdvanced Data Analysis(旧Code Interpreter)がローカルで動くぞ、みたいなものです。Open Interpreterを通じて、GPT-4、GPT-3.5、Code Llamaなどのコード生成AIを利用することになります。
詳細は、下記の公式サイトを参照
https://github.com/KillianLucas/open-interpreter
GPT-4、GPT-3.5はローカルではなくAPI経由でOpenAIにアクセスしていますが、Code Llamaはローカルで動いているものが利用できます。これはすごいですね。
じゃあ、GPT4、GPT-3.5は意味がないかというと、AIがコード作成に必要だと判断したパッケージをインストール(pythonの場合)して動くので、必要なライブラリをどんどん入れてくれます。ChatGPTのチャット画面で打ち込むよりも多くのことができそうです。
上記で挙げたコード生成AI以外にもOpen Interpreterの引数にモデルを指定すると使ってくれる機能もあるので、色々なAIを試せそうです。
Open Interpreterのセットアップ
仕事で使っている端末はM1 macbookなのですが、Stable Diffusionで遊ぶために購入したWindowsマシンが暇だと訴えてくるので、仕方なく、本当に仕方なく、Windowsマシンにセットアップすることにしました。
なお、GPT-3.5やGPT-4をAIとして利用するケースでは、M1 macbookでも快適に動くことを確認していますが、以下ではWindows上で試しています。
Windows(WSL2)+Code Llama
「素のWindowsじゃないんだ・・」と聞こえてきそうですが、以下の理由でWSL2にしました。
- powerShell上でCtrl+Cで止まらないことがある
- 「-y」オプションなしなのに、勝手にフォルダを作ったりしようとして落ちる・・・
WSL2環境のパッケージ更新
WSL2のパッケージを更新します。WSL2で動いているのは「Ubuntu 22.04.3 LTS」です。以下は、Ubuntuのターミナルから実行。
$ sudo apt update
$ sudo apt list --upgradable
$ sudo apt upgradepython仮想環境の作成
Open Interpreterが自由気ままにpythonパッケージをインストールしてしまうので、とりあえずシステムのpython環境とは隔離しておきます。今回は、Anacondaするほどでもなかった&Anacondaは最初から大量のパッケージがあって干渉が怖かったので、venvを使いました。pythonは3.10系です。
# 今の環境を見てみる(pipすらない場合)
$ pip
Command 'pip' not found, but can be installed with:
# 仮想環境を作る(隔離環境の方が正しい用語?)
$ sudo apt install python3-pip
$ sudo apt install python3.10-venv
$ mkdir -p ~/ai/open-interpreter
$ cd ~/ai/open-interpreter
$ python3 -m venv ./venv
# 有効化
$ . ./venv/bin/activate
# 確認(pipくらい入ったよね?)
$ pip list
Package Version
---------- -------
pip 22.0.2
setuptools 59.6.0open-intepreterインストール
$ pip install open-interpreter驚くほど簡単。素晴らしい。
llama-cpp-pythonのインストール
Open InterpreterでサポートしているCode LlamaのモデルはGGUF形式。そして、これを裏で「llama-cpp-python」が動かしているようです。
という訳で、「ローカルPCでLLMを動かす(llama-cpp-python)」の
「llama-cpp-pythonのインストール(WSL2版)」→「(ケース2)llama-cpp-pythonのインストール(CPU+GPUで動かす場合)」の手順を見て、llama-cpp-pythonをインストールしてください。

なお、ローカルPCにNVIDIA GeForceなんて無いよ!という方は、「llama-cpp-pythonのインストール(WSL2版)」→「(ケース1)llama-cpp-pythonのインストール(CPUだけで動かす場合)」を見てください。動作は遅いですが、動きます。
参照先の手順とは作業ディレクトリが別の場所を指しているので、読み替えてください
動作確認
# デバッグモードで起動
$ interpreter --local --debug
Open Interpreter will use Code Llama for local execution. Use your arrow keys to set up the model.
[?] Parameter count (smaller is faster, larger is more capable): 7B
> 7B
13B
34B
# 13Bを選ぶ(もちろん、34Bの方が良いのですが、信じられないくらい重い or 動かない)
[?] Parameter count (smaller is faster, larger is more capable): 13B
7B
> 13B
34B
[?] Quality (smaller is faster, larger is more capable): Small | Size: 5.1 GB, Estimated RAM usage: 7.6 GB
> Small | Size: 5.1 GB, Estimated RAM usage: 7.6 GB
Medium | Size: 7.3 GB, Estimated RAM usage: 9.8 GB
Large | Size: 12.9 GB, Estimated RAM usage: 15.4 GB
See More
# Mediumを選ぶ(Largeを選べるのはRTX4080、4090を持っている勇者だけ)
[?] Quality (smaller is faster, larger is more capable): Large | Size: 12.9 GB, Estimated RAM usage: 15.4 GB
Small | Size: 5.1 GB, Estimated RAM usage: 7.6 GB
> Medium | Size: 7.3 GB, Estimated RAM usage: 9.8 GB
Large | Size: 12.9 GB, Estimated RAM usage: 15.4 GB
See More
[?] Use GPU? (Large models might crash on GPU, but will run more quickly) (Y/n):
# Yを入力してGPUを選ぶ
Y
This language model was not found on your system.7GBくらいのモデルをダウンロードします。それなりに時間はかかります。
ダウンロードしたファイルは以下に配置されます。
$ ll ~/.local/share/Open\ Interpreter/models/
total 7681732
drwxr-xr-x 2 takehara takehara 4096 Sep 14 13:53 ./
drwxr-xr-x 3 takehara takehara 4096 Sep 14 13:49 ../
-rwxrwxrwx 1 takehara takehara 7866070016 Sep 13 21:24 codellama-13b-instruct.Q4_K_M.gguf*モデルダウンロードは初回だけで、2回目以降はモデルファイルのパス名が表示されます。
llama-cpp-pythonがCUDA対応になっているかどうかは、ここで判明します。
モデルダウンロード後に行われるロードの際に出てくる大量のメッセージを見ます。
そして、最後の付近に出てくるメッセージを見てください。
AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1| SSE3 = 1 | SSSE3 = 1 | VSX = 0 |BLAS=1になっていればOK。この後は、Ctrl + Cで終了させます。(debugオプションをつけたため表示がうるさい)
検証1:素数を数えさせる
素数なんて滅多に数えませんが、ChatGPTは数学が苦手なので試してみました。
1から50までの数字の中で素数を求める処理をpythonで書いてください以下では色なしですが、実際に動くものは、カラフルでもっと見やすいです。
なお、オレンジハイライトの部分は、手入力したことを示します。
Code Llama + Open Interpreter
Code Llamaで動かすには、引数「–local」が必要です。
$ interpreter --local
...(省略)...
▌ Model set to TheBloke/CodeLlama-13B-Instruct-GGUF
...(省略)...
> 1から50までの数字の中で素数を求める処理をpythonで書いてください
1 through 50 is a range of numbers. We need to find all the prime numbers within that range.
import math
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True
primes = []
for i in range(1, 51):
if is_prime(i):
primes.append(i)
print(primes)
Would you like to run this code? (y/n)
y
import math
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True
primes = []
for i in range(1, 51):
if is_prime(i):
primes.append(i)
print(primes)
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
2 through 50 is a range of numbers. We need to find all the prime numbers within that range.
無事動きました。コード生成はかなり速いです。
いまは「-y」オプションをつけていないので、「Would you like to run this code? (y/n)」で聞いてきますが、「-y」をつけると全自動でやってくれます。
最後の1行が最初の1行の繰り返しでになっています。実は、このあとずーーと、同じコードを吐き出しては「Would you like to run this code? (y/n)」させられました。「-y」しなかった理由はここにあります。怖すぎる。
まあ、いいでしょう。素数は出せました。
GPT-3.5+Open Interpreter
GPT-3.5で動かすには、引数「–fast」と環境変数によるAPIキーの指定が必要です。
APIキーは、OpenAIのサイトで発行したChatGPT APIと同じものを指定します。
$ export OPENAI_API_KEY=(APIキー)
$ interpreter --fast
...(省略)...
▌ Model set to GPT-3.5-TURBO
...(省略)...
> 1から50までの数字の中で素数を求める処理をpythonで書いてください
Sure! Here's the Python code to find prime numbers from 1 to 50:
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
prime_numbers = []
for num in range(1, 51):
if is_prime(num):
prime_numbers.append(num)
print(prime_numbers)
This code defines a function is_prime() to check if a number is prime or not. Then, it iterates through the
numbers from 1 to 50 and adds the prime numbers to a list. Finally, it prints the list of prime numbers.
Let me know if you need any further assistance!
>実行しないで終わってしまいました。あ、「実行してください」と言えば良かったのかも。
> 上記のコードを実行して素数を出力してください
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
prime_numbers = []
for num in range(1, 51):
if is_prime(num):
prime_numbers.append(num)
prime_numbers
Would you like to run this code? (y/n)
Y
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
prime_numbers = []
for num in range(1, 51):
if is_prime(num):
prime_numbers.append(num)
prime_numbers
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
実行結果は以下の通りです。
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
1から50までの数字の中で素数となる数値が出力されました。
>はい、問題なしです。
※(2023/09/25追記)9/24にリリースされたバージョン「0.1.5」からは「–fast」が非推奨オプションになりました。実行すると、こんな警告が出てきます。
$ interpreter --fast
`interpreter --fast` is depracated and will be removed in the next version. Please use `interpreter --model gpt-3.5-turbo`今度からは「interpreter –model gpt-3.5-turbo」と入力しましょう。(ちょっと長いですよね)
GPT-4+Open Interpreter
GPT-4で動かすには、環境変数によるAPIキーの指定が必要です。その他の引数は不要。
Open Interpreter的にはGPT-4がおすすめということです。
$ export OPENAI_API_KEY=(APIキー)
$ interpreter
...(省略)...
▌ Model set to GPT-4
...(省略)...
> 1から50までの数字の中で素数を求める処理をpythonで書いてください
まず、以下の手順で素数を求めるプログラムを作成します。
1 1から50までの数字を生成します。
2 各数字が素数であるかどうかをチェックします。素数は1とその数自身以外の数で割り切れない数です。
3 素数である数字をリストに追加します。
それでは、まず1から50までの数字を生成するコードを書きます。
numbers = list(range(1, 51))
numbers
Would you like to run this code? (y/n)
y
numbers = list(range(1, 51))
numbers
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,
30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]
1から50までの数字が生成されました。
次に、各数字が素数であるかどうかをチェックする関数を作成します。この関数は、与えられた数が素数であればTrueをそうでなければFalseを返します。
def is_prime(n):
if n < 2:
return False
for i in range(2, n):
if n % i == 0:
return False
return True
# Test the function
is_prime(7)
Would you like to run this code? (y/n)
y
def is_prime(n):
if n < 2:
return False
for i in range(2, n):
if n % i == 0:
return False
return True
# Test the function
is_prime(7)
True
素数をチェックする関数が正しく動作しています(7は素数なのでTrueを返します)。
次に、この関数を使用して1から50までの各数字が素数であるかどうかをチェックし、素数のリストを作成します。
primes = [n for n in numbers if is_prime(n)]
primes
Would you like to run this code? (y/n)
y
primes = [n for n in numbers if is_prime(n)]
primes
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
1から50までの数字の中で素数は以下の15個です:
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47
これらの数字は1とその数自身以外の数で割り切れないため、素数と定義されます。
>まじか、丁寧すぎる。さすがGPT-4です。
GPT-3.5のAPI使用料が20倍なだけあります。Usage見るのが怖い・・・
検証2:外部APIを呼び出す
もう辛くなってきました。いやいや、素数なんて業務プログラムで組むことないんです。
次は、外部APIを呼び出す検証をします。これくらいサッと呼べないと使い物になりませんね。さっきのはちょっと題材がイマイチでした。
郵便番号を引数として受け取り、住所を検索する処理をpythonの関数として作ってください。郵便番号検索は、次の外部APIをPOSTで呼びます。リクエストURL「https://(URLはマスクしました)」、HTTPヘッダ「Content-Type: application/json」、Bodyデータには郵便番号7桁の数字を指定する。試し実行するために、郵便番号「1310045」を使ってください。この時に外部APIから取得する住所は「東京都」「墨田区」「押上」になるはずです。長くて、わかりにくい。改行入れると実行されてしまうので、1行に詰め込みました※。郵便番号を検索する外部APIを呼び出して、「東京都墨田区押上」の住所が出ることを確認してもらうことにしました。なお、URLはサイトに載せる際にマスク化しています。
※「Shift+Enter」しても改行ではなく実行されてしまうのです。
これはちょっと使いにくい。別の方法あるのかな。
Code Llama+Open Interpreter
...(コード書くところまで省略)...
import requests
def get_address(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = {
"zipcode": zipcode,
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
return response.json()["address"]
else:
raise Exception("Error in getting address")
Would you like to run this code? (y/n)
n> bodyには郵便番号をそのまま指定します。json形式変更変更は不要です
import requests
def get_address(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = {
"zipcode": zipcode,
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
return response.json()["address"]
else:
raise Exception("Error in getting address")
Would you like to run this code? (y/n)
n
> 違います。requests.postの第3引数には郵便番号を形式変換せずにそのまま渡してください
...(また同じコード)...
> requests.post(url, headers=headers, data=zipcode)と書いてください
...(また同じコード)...このあと、CPUをぶん回したまま長考に入ってしまったので、Ctrl+Cしました。
その後、何度か実行しましたが、コードを直してくれませんでした。MetaのLlama系は英語のデータセットで訓練されているので、日本語だと難しいのかな。
GPT-3.5+Open Interpreter
...(コード書くところまで省略)...
プラン:
1 外部APIにPOSTリクエストを送信するためのPythonの関数を作成します。
2 関数に郵便番号を引数として渡し、APIからのレスポンスを受け取ります。
3 レスポンスから住所を抽出して返します。
コードを実行する前に、必要なパッケージをインストールします。
Would you like to run this code? (y/n)
y
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = {"zipcode": zipcode}
response = requests.post(url, headers=headers, json=data)
address_data = response.json()
address = address_data["address"]
return address
Would you like to run this code? (y/n)
n
> body には郵便番号を直接指定すること。json形式にする必要はありません。
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = zipcode
response = requests.post(url, headers=headers, data=data)
address_data = response.json()
address = address_data["address"]
return address
Would you like to run this code? (y/n)
y
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = zipcode
response = requests.post(url, headers=headers, data=data)
address_data = response.json()
address = address_data["address"]
return address
関数が正常に作成されました。郵便番号を引数として関数を呼び出すと、外部APIから取得した住所が返されます。郵便番号「1310045」を使用して試してみましょう。
search_address_by_zipcode('1310045')
Would you like to run this code? (y/n)
y
search_address_by_zipcode('1310045')
File "<stdin>", line 4, in <module>
File "<stdin>", line 18, in search_address_by_zipcode
KeyError: 'address'
申し訳ありませんが、APIからのレスポンスに「address」というキーが含まれていないようです。APIの仕様に
問題がある可能性があります。もう一度確認してみてください。
> adressというキーはもありません。responseを取得して、どのようなキーがあるのか調べてください
response.json()
Would you like to run this code? (y/n)
y
response.json()
File "<stdin>", line 4, in <module>
NameError: name 'response' is not defined
申し訳ありませんが、エラーが発生しました。関数内でresponse変数を定義する必要があります。修正してもう一度試してみましょう。
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = zipcode
response = requests.post(url, headers=headers, data=data)
address_data = response.json()
return address_data
Would you like to run this code? (y/n)
y
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = zipcode
response = requests.post(url, headers=headers, data=data)
address_data = response.json()
return address_data
response = search_address_by_zipcode('1310045')
response.keys()
Would you like to run this code? (y/n)
y
response = search_address_by_zipcode('1310045')
response.keys()
dict_keys(['result'])
APIからのレスポンスには、"result"というキーが含まれているようです。このキーの値を確認してみましょう。
response['result']
Would you like to run this code? (y/n)
y
response['result']
{'message': None, 'results': [{'address1': '東京都', 'address2': '墨田区', 'address3': '押上', 'kana1':
'トウキョウト', 'kana2': 'スミダク', 'kana3': 'オシアゲ', 'prefcode': '13', 'zipcode': '1310045'}], 'status': 200}
APIからのレスポンスには、"results"というキーが含まれています。このキーの値には、住所情報が含まれています。具
、"address1"が都道府県名、"address2"が市区町村名、"address3"が町域名です。それぞれの値を取得して返すように関数を修正しましょう。
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = zipcode
response = requests.post(url, headers=headers, data=data)
address_data = response.json()
results = address_data['results']
if results:
address = results[0]['address1'] + results[0]['address2'] + results[0]['address3']
return address
else:
return 'No address found.'
Would you like to run this code? (y/n)
y
import requests
def search_address_by_zipcode(zipcode):
url = "https://(URLはマスクしました)"
headers = {"Content-Type": "application/json"}
data = zipcode
response = requests.post(url, headers=headers, data=data)
address_data = response.json()
results = address_data['results']
if results:
address = results[0]['address1'] + results[0]['address2'] + results[0]['address3']
return address
else:
return 'No address found.'このあと、ずっと止まらなくなってしまったので、結果がわかりませんでした。
ただ、途中で自分でresponseを調べるように指示したら勝手にやってくれたので、非常に良い感じです。いまは起動オプションに「-y」付けたら自分で気づいて自分で訂正してくれるはずなので、これは希望が持てます。賢すぎる。課金が怖いけど。
GPT-4+Open Interpreter
...(コード書くところまで省略)...
了解しました。以下の手順で進めていきます。
1 必要なパッケージをインストールします。このタスクでは、外部APIを呼び出すためにrequestsパッケージが必要です
。
2 郵便番号を引数として受け取り、指定されたAPIにPOSTリクエストを送信し、結果を返すPython関数を作成します。
3 作成した関数をテストします。郵便番号「1310045」を引数として関数を呼び出し、結果が「東京都」「墨田区」「押上」になることを確認します。
まず、必要なパッケージをインストールします。すでにインストールされている場合はこのステップをスキップしてください。
!pip install requests
Would you like to run this code? (y/n)
n
> パッケージはすでにあるので、2以降を続けてください
了解しました。次に、郵便番号を引数として受け取り、指定されたAPIにPOSTリクエストを送信し、結果を返すPython関数を作成します。この関数は、引数として郵便番号を受け取り、指定されたAPIにPOSTリクエストを送信します。そのレスポンスを解析し、住所情報を返します。
import requests
import json
def search_address(zip_code):
url = 'https://(URLはマスクしました)'
headers = {'Content-Type': 'application/json'}
data = json.dumps({'zipCode': zip_code})
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
return response.json()
else:
return None
Would you like to run this code? (y/n)
n
> bodyに渡すデータは郵便番号の数値だけです。json形式にする必要はありません
了解しました。郵便番号を直接BodyデータとしてPOSTリクエストに含めるように関数を修正します。
import requests
def search_address(zip_code):
url = 'https://(URLはマスクしました)'
headers = {'Content-Type': 'application/json'}
data = str(zip_code)
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
return response.json()
else:
return None
Would you like to run this code? (y/n)
y
import requests
def search_address(zip_code):
url = 'https://(URLはマスクしました)'
headers = {'Content-Type': 'application/json'}
data = str(zip_code)
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
return response.json()
else:
return None
関数の作成が完了しました。次に、この関数をテストします。郵便番号「1310045」を引数として関数を呼び出し、結果が「東京都」「墨田区」「押上」になることを確認します。
search_address(1310045)
Would you like to run this code? (y/n)
y
search_address(1310045)
{'result': {'message': None, 'results': [{'address1': '東京都', 'address2': '墨田区', 'address3': '押上',
'kana1': 'トウキョウト', 'kana2': 'スミダク', 'kana3': 'オシアゲ', 'prefcode': '13', 'zipcode': '1310045'}], 'status':
200}}
関数が正しく動作し、郵便番号「1310045」に対して「東京都」「墨田区」「押上」の住所情報を取得できました。これで郵便番号を引数として受け取り、住所を検索するPython関数の作成が完了しました。あまりにあっさりと終わったので、「やっぱり住所文字列は間を半角スペースで区切ってね」と後出し仕様を追加します。
> レスポンスのaddress1,address2,address3を半角スペース区切りで結合した文字列を返す関数にしてください
了解しました。関数を修正して、レスポンスのaddress1、address2、address3を半角スペースで結合した文字列を返すようにします。
def search_address(zip_code):
url = 'https://(URLはマスクしました)'
headers = {'Content-Type': 'application/json'}
data = str(zip_code)
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
result = response.json()
address = result['result']['results'][0]
return ' '.join([address['address1'], address['address2'], address['address3']])
else:
return None
Would you like to run this code? (y/n)
y
def search_address(zip_code):
url = 'https://(URLはマスクしました)'
headers = {'Content-Type': 'application/json'}
data = str(zip_code)
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
result = response.json()
address = result['result']['results'][0]
return ' '.join([address['address1'], address['address2'], address['address3']])
else:
return None
関数の修正が完了しました。再度、郵便番号「1310045」を引数として関数を呼び出し、結果が「東京都 墨田区
押上」になることを確認します。
search_address(1310045)
Would you like to run this code? (y/n)
y
search_address(1310045)
'東京都 墨田区 押上'
関数が正しく動作し、郵便番号「1310045」に対して「東京都 墨田区
押上」の住所情報を取得できました。これで郵便番号を引数として受け取り、住所を検索するPython関数の作成が完了しました。すばらしい。わかりやすく、ちゃんと訂正に応じてくれます。
(おまけ)プロンプトで使える特殊コマンド
9/14の実験中にバージョンが「0.1.4」に上がったようで、下記が使えるようになりました。
先ほどはデバッグモードで起動したinterpreterをCtrl+Cしていましたが「%debug false」で済むようになります。python上でしか使えなかった命令がターミナルから使えるようになり非常に便利。
%debug [true/false]: Toggle debug mode. Without arguments or with ‘true’, it enters debug mode. With ‘false’, it exits debug mode.%reset: Resets the current session.%undo: Remove previous messages and its response from the message history.%save_message [path]: Saves messages to a specified JSON path. If no path is provided, it defaults to ‘messages.json’.%load_message [path]: Loads messages from a specified JSON path. If no path is provided, it defaults to ‘messages.json’.- •
%help: Show the help message.
(おまけ)interpreterコマンドの引数(2023/9/25追記)
9/24リリースの「0.1.5」からはinterpreterコマンドの引数が変わりました。
0.1.5よりも前(0.1.3かもしれない・・)
usage: interpreter [-h] [-y] [-f] [-l] [--falcon] [-d] [--model MODEL] [--max_tokens MAX_TOKENS] [--context_window CONTEXT_WINDOW] [--api_base API_BASE] [--use-azure] [--version]
Chat with Open Interpreter.
options:
-h, --help show this help message and exit
-y, --yes execute code without user confirmation
-f, --fast use gpt-3.5-turbo instead of gpt-4
-l, --local run fully local with code-llama
--falcon run fully local with falcon-40b
-d, --debug prints extra information
--model MODEL model name (for OpenAI compatible APIs) or HuggingFace repo
--max_tokens MAX_TOKENS
max tokens generated (for locally run models)
--context_window CONTEXT_WINDOW
context window in tokens (for locally run models)
--api_base API_BASE change your api_base to any OpenAI compatible api
--use-azure use Azure OpenAI Services
--version display current Open Interpreter version0.1.5
結構増えましたね。「–falcon」が消えて「–fast」が非推奨になったのが影響ありです。統一的に「–model」にしたようです。「–config」でconfig.yamlに設定を書いておけるようになったのはいいですね。
usage: interpreter [-h] [-s SYSTEM_MESSAGE] [-l] [-y] [-d] [-m MODEL] [-t TEMPERATURE] [-c CONTEXT_WINDOW] [-x MAX_TOKENS] [-b MAX_BUDGET] [-ab API_BASE] [-ak API_KEY] [--config] [--conversations] [-f]
Open Interpreter
options:
-h, --help show this help message and exit
-s SYSTEM_MESSAGE, --system_message SYSTEM_MESSAGE
prompt / custom instructions for the language model
-l, --local run in local mode
-y, --auto_run automatically run the interpreter
-d, --debug_mode run in debug mode
-m MODEL, --model MODEL
model to use for the language model
-t TEMPERATURE, --temperature TEMPERATURE
optional temperature setting for the language model
-c CONTEXT_WINDOW, --context_window CONTEXT_WINDOW
optional context window size for the language model
-x MAX_TOKENS, --max_tokens MAX_TOKENS
optional maximum number of tokens for the language model
-b MAX_BUDGET, --max_budget MAX_BUDGET
optionally set the max budget (in USD) for your llm calls
-ab API_BASE, --api_base API_BASE
optionally set the API base URL for your llm calls (this will override environment
variables)
-ak API_KEY, --api_key API_KEY
optionally set the API key for your llm calls (this will override environment
variables)
--config open config.yaml file in text editor
--conversations list conversations to resume
-f, --fast (depracated) runs `interpreter --model gpt-3.5-turbo`https://github.com/KillianLucas/open-interpreter/blob/main/README.md
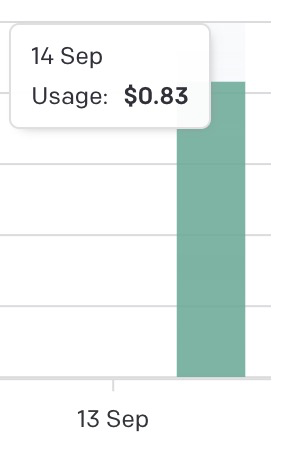
本日の課金
GPT-3.5を使っている時には、$0.06くらいでしたが、GPT-4を使ったら一気に上がりました。GPT-4非常に賢いのですが、少し悩みますね(会社の財布なら気にしないのだけど・・・)
使ってみた感想
Open Intepreter
まだまだ全部のコードを書いてもらうことは難しそうですが、関数単位など部品を作る能力は十分と感じました。PCを操作したりすることもできてしまうので、単なるコード作成補助以上の使い道がありそうです。
各種モデル比較
| モデル | 使い勝手 |
| Code Llama | GPUが利用できれば最も高速。ただ、プロンプトの通りに生成させるのは大変。今回はパラメータ数が低いものしかローカルでは動かなかったので、その力を十分に確認できなかった。パラメータ数が大きいモデルは民生品のPCでは動かないので、クラウドに載せて利用するしかないのだが、そうするとクラウドの利用料金もかかってしまい、そのトレードオフが悩みどころ。 |
| GPT-3.5 | 思ったよりも健闘したと思う。ChatGPTの画面から叩いた結果と比べると説明内容が何故かシンプルになった気がするが、書いたコードをその場で実行できるのは非常に便利と感じた。 GPT-4に比べてAPIの利用料が20分の1なので、もう少しプロンプトを正確にしたり、ステップバイステップでチャットのようにAIとやりとりできれば精度が上がるだろう。 |
| GPT-4 | 圧倒的。AIに頼るときには結果だけではなく、その過程も知りたいと思うはずなので、その点も指示もせず暗黙のうちにやってくれるのは素晴らしい。API利用料金も圧倒的なのが痛い。 |
まとめ
以上、Open Interpreterをつかってみた、でした。
「保険料計算を入力値を集める画面を作ってみる」「Reactコンポーネントを作らせて、Reduxに情報を詰めてもらう」「テストコードを書かせる」とか実務でこれくらいはできて欲しい、というところも検証をしたかったのですが、まさかのCode Llamaのセットアップに躓いてあまりできませんでした。。
Open Interpreterも更新が掛かっているようなので、この記事が投稿される時には状況が変わっているかもしれません。面白いプロダクトなので、引き続き注視していきたいと思います。